5.10 Diff-in-diff-analyse
Diff-in-diff er en mye brukt analyseform der man analyserer effekten av en «behandling» gjennom å sammenlikne endringen i gjennomsnittsverdien for en kontinuerlig/rangerbar responsvariabel før/etter behandlingstidspunktet. Dette gjøres for to grupper:
-
Behandlingsgruppen
-
Kontrollgruppen
Til slutt finner man differansen mellom de to gruppene.
Følgende forberedende trinn må følges før man kan kjøre en diff-in-diff-analyse:
-
Opprett et paneldatasett gjennom kommandoen
import-paneleller ved å konvertere fra «wide»-format til «long»-format gjennom kommandoenreshape-to-panel. -
Lag en gruppevariabel med verdien 1 for behandlingsgruppen og 0 for kontrollgruppen.
-
Lag en behandlingsvariabel som settes til 0 for alle tidspunkter før behandlingstidspunktet, og 1 for alle tidspunkter fra og med behandlingstidspunktet.
Etter å ha fulgt trinnene 1. - 3. brukes kommandoen
regress-panel-diff.
Den avhengige variabelen listes først. Den må være kontinuerlig eller rangerbar. Gruppe- og behandlingsvariablene skal listes som nummer 2 og 3. Dette er en forutsetning for at analysen skal bli riktig gjennomført. Øvrige uavhengige variabler listes til slutt (valgfritt).
Resultatet av regress-panel-diff viser en standard
panelregresjonstabell med modellmål og koeffisientverdier.
Diff-in-diff-verdien (såkalt ATET-verdi - average treatment effect of the treated) tilsvarer koeffisientverdien til interaksjonsleddet for de to dummyvariablene som angir hhv. gruppe og «behandling».
Eksempel:
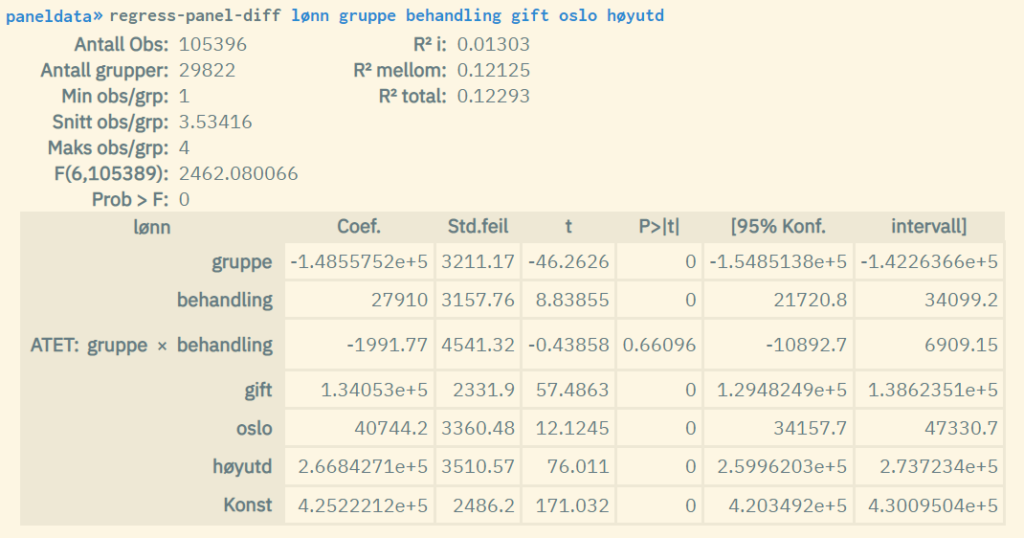
Kommandoen regress-panel-diff tilsvarer å kjøre regress-panel med opsjonen pooled der gruppe-og behandlingsvariablene inngår som interaksjonsledd samt separate dummyer (bruker tegnene ## for å uttrykke dette).
Eksempel:
regress-panel-diff lønn gruppe behandling gift oslo høyutd
gir samme resultat som
regress-panel lønn gruppe##behandling gift oslo høyutd, pooled
Følgende opsjoner er tilgjengelige for regress-panel-diff:
-
level(): Definer et annet signifikansnivå enn standardverdien 95 (5% signifikansnivå) -
robust: Robuste standardavvik -
cluster(): Cluster-estimering
Kommandoen help regress-panel-diff gir mer informasjon om de tilgjengelige alternativene.
Tid (f.eks. faktorledd som i.år) bør ikke inngå i regress-panel-diff-modeller ettersom man da vil kunne få 100% lik varians for behandlingsvariabelen sammenliknet med dummyleddene knyttet til årene fra og med behandlingstidspunktet. Koeffisientestimatene for de involverte variablene/leddene vil da bli feil.
Eksempel på tilrettelegging av data for diff-in-diff-analyse
Dersom man lager et paneldatasett ved hjelp av import-panel, behandles måletidspunkter med UnixTime-formatet, og man må da bruke funksjonen year() for å hente ut / angi årstallet, slik som i eksempelet over:
replace behandling = 1 if year(date@panel) >= 2020
Bruker man i stedet reshape-to-panel til å lage et paneldatasett, er det du som styrer verdiformatet på måletidspunktene gjennom bruk av suffiks på variablene (vanligvis tosifret eller firesifret årstall), og du må da passe på å tilpasse replace-uttrykket slik at det passer med formatet på date@panel. Bruker du suffiks som angir firesifret årstall (YYYY), blir dette også formatet på verdiene til date@panel. Da skal du ikke bruke year() siden denne kun er beregnet til bruk på UnixTime-formater. I dette tilfellet må du angi årstallet slik:
replace behandling = 1 if date@panel >= 2020